| 
序论:在上一期的C位不雅察中,咱们共享了关于生成式AI带来的技艺翻新和产业落地的念念考。在全球尽情期待、拥抱和体验生成式AI和大模子的同期,咱们也廓清地看到,中好意思在AI领域的相助和竞争是挑战和机遇的并存。因此,咱们需要直面若何理清国内的优颓势,把各个关键进行拆解并达成追逐。从AI三成分即数据、算法、算力分歧来看,数据和应用场景是国内AI行业的上风,算法模子上的差距也在冉冉削弱,但算力依然是当今公认的最需要蹈厉奋发的关键。
为了达成算力层面的擢升和追逐,国内有无数的厂商和从业者在各个产业链关键发奋。但濒临中短期内架构、制程、产能、出口禁令等多方面的制约,咱们以为从芯片层面达成单点的冲破依旧是止境繁难且不及的。相干词,借助国内电力、基建的上风,通过多卡、多节点、多集群的方式,以皆备数目上的堆积来取得冲破,将是一条可行的旅途。其实,全球行业的发展也正降服着这个趋势,AI算力集群正从千卡向万卡以致十万卡的范围演进。这个冲破标的的关键是若何搭建起宽绰的集群,若何让千卡/万卡能拧成一股绳以阐述更好的能效,咱们以为互联通讯将在其中上演至关迫切变装。因此本文主要会就数据中心内的互联通讯,尤其是节点/集群间的通讯,与全球进行共享交流。
(一) 算力、存储、互联通讯-构建AI算力集群“高速交通系统”三成分
欣然模子时期开启以来,产业界沿着Scaling Law在合手续连续推出更大参数的模子和更多模态的模子,由此带来的海量数据的汇聚、分析和应用,使全行业的算力需求以惊东谈主的速率激增。据统计,大模子检修关于算力的需求约每三个月翻一倍。能否取得更多、更高效的算力,成为了各个“玩家”最中枢的竞争力之一。在这波此伏彼起的囤卡、搭集群、建数据中心的“武备竞赛”中,在摩尔定律迫临极限、单靠制程和架构带来的单卡算力角落擢升后果放缓的布景下,除了损失无数资金和资源取得计较卡、劳动器皆备数目的囤积上风外,如安在本色场景下充分阐述这些AI芯片的性能、若何合手续擢升数据中心合座的数据计较和处理后果,是产业正在探索的另一种可能一本万利的标的。
平庸来看,要是将一个AI智算中心类比为以数据为中心的大型的交通输送汇聚,那么构建和运行这个输送汇聚最中枢的三个成分等于算力、存储和互联通讯。在这个大型输送汇聚中,要是咱们以为每一个计较集群等于一个空洞交通关键,那么算力主要治理的是这个交通关键内单个站点的流量通行速率问题,存储主要治理的是单个站点的流量上限问题,互联通讯主要治理的是关键里面站点和站点之间,以及关键和关键之间的运力问题。三者相得益彰、三管皆下来擢升系数输送汇聚的运行速率和后果。

图1:算力、存储、互联通讯,构建数据中心“高速交通系统”的三成分
若何系统性地拓展这个“高速交通系统”用以处理更大范围的使命任务?当今业界主要有两种方式:1)Scale-up(朝上/垂直扩张):通过增多单个系统的资源(如芯片算力、内存或存储容量)来擢升其性能,即让一个单一的系统变得愈加强盛; 2)Scale-out(横向/水平扩张):通过增多更多的一样或相似建树的系统来分散使命负载,即添加更多的孤苦系统来共同完成任务。
延续前述交通关键的类比,Scale-up是针对单一关键的扩容,用更大和更多的站点来擢升里面承载和通行才智,比如英伟达通过集成36颗GB200x芯片推出的DGX GB200系统。而Sclae-out则是诞生和接入更多的关键来扩大合座的输送汇聚,例举英伟达DGX SuperPOD,不错集成至少8个以致更多DGX GB200系统,并通过连续的拓展来达成数万颗GB200芯片的聚拢。 新金瓶梅

图2:Scale-up vs Scale-out
从图2中,咱们不错明晰地看到,算力和存储主要聚焦的如故Scale-up下单个关键内站点的范围和笼统才智,无数的优化擢升其实是来自于基础设施硬件的性能和软硬件的协同,对此业界通过架构、制程、介质、软件生态等多个方面依然作念出了无数的发奋,国表里也已露馅出一批优质的企业。
但治理Scale-up后关键内越来越多站点的接入和站点间运力问题,以及Scale-out后越来越多关键的连接和输送问题,则需要构建更好的输送才智,即互联通讯的才智。与此同期,咱们也不雅察到数据中心合座范围和本色性能&后果擢升的天花板,更多地从以往算力的管束滚动为互联通讯的管束。换而言之,咱们以为明天集群后果的擢升重心会从计较滚动为汇聚。因此,本文会将翰墨重心放在构建高速通谈、撑合手和擢升点到点之间运力才智的互联通讯领域。

图3:I/O带宽与算力之间的差距渐渐扩大

图4:AI算力基础设施需要更好的互联通讯才智,冲破计较后果和范围瓶颈
(二) 互联通讯-AI计较集群的快速通谈系统,治理关键内和关键间的输送后果
AI计较集群的互联通讯才智系统性的构建,主要来自三个方面,由内到外不错分为1)Die-to-Die(裸片间)互连:发生在芯片封装内,达成芯片里面不同功能模块间的数据交换;2)Chip-to-Chip(片间)互联:达成劳动器里面,主板上不同芯片间(如 CPU-GPU,GPU-GPU)的数据通讯;3)Board-to-Board(机间)互联:在劳动器外部的通讯,达成劳动器-交换机、交换机-交换机之间的数据传输,并层层近似形成数据中心集群的组网架构。

图5:数据中心各层级互联通讯暗示
为何英伟达在计较领域能如斯强势?除了耳闻目睹的芯片架构和CUDA软件生态外带来的单芯片的性能上风外,其在互联通讯领域的多年布局,打出的一套面向Scale-up(NV Link、NV Switch)和面向Scale-out (InfiniBand) 的组合拳,使得其在节点和集群层面的性能和后果遥遥进步。

图6:英伟达DGX H100 SuperPod里面汇聚架构
从技艺发展阶梯来看,Die-to-Die通讯才智的擢升当今主要依赖于2.5D/3D的先进封装和愈加长入方法的高速Serdes等,Chip-to-Chip互联主要依靠更高速的PCIE、CXL公约以及英伟达私有的NVLink技艺等,但这两条阶梯主要治理的如故芯片和劳动器里面的通讯后果,即咱们前文提到的若何治理Scale-up的问题,这部天职容咱们会在明天的系列著述中作念更多的商酌。但咱们以为, Scale-up因为受到物理空间、布线、工程达成等制约,合座可拓展的后劲和范围有限,而Scale-out手脚Scale-up的进一步延续,会更具范围性和拓展后劲。
在大模子时期,过往传统AI单卡、单劳动器或者单机柜即可治理的计较任务,已指数级地擢升到需要千卡、万卡以致是十万卡的分散式集群来撑合手。因此,若何擢升劳动器外部Board-to-Board、节点间/集群间的互联通讯才智,治理前边说的更为关键的Scale-out带来的通讯挑战,来构建系数数据中心的“高速输送汇聚”,变得越来越迫切。那么若何达成大范围的Scale-up?大模子时期需要什么样的数据中心汇聚?需要什么样的软硬件和技艺撑合手?咱们不错连续往下一探究竟。
(三) 聚焦关键间的通走时送后果,治理Scale-up的问题,大模子时期需要什么样的数据中心汇聚?
大模子数据检修量大,且主要通过数据并行和模子并行进行检修,因此需要遴选分散式集群、多节点的检修方式,且节点之间需要进行中间计较赶走的及时高频通讯,由此带来数据通讯的两个新的大趋势:1)汇聚流量大幅增长;2)由传统数据中心的南北向流量为主转为AI数据中心的东西向流量为主。

图7:全球汇聚流量保合手高速增长

图8:南北向流量往东西向流量滚动
为了提高AI芯片灵验计较期间占比、幸免汇聚蔓延和带宽法规负担AI检修后果,对新式的AI数据中心通讯汇聚建议超大范围组网、超高带宽、超低时延及抖动、超高踏实性和汇聚自动化部署等无数新的需求,并促使汇聚架构更新升级,从典型汇聚架构(树型)转向多中枢、少抑止形态(胖树型、脊叶型)。
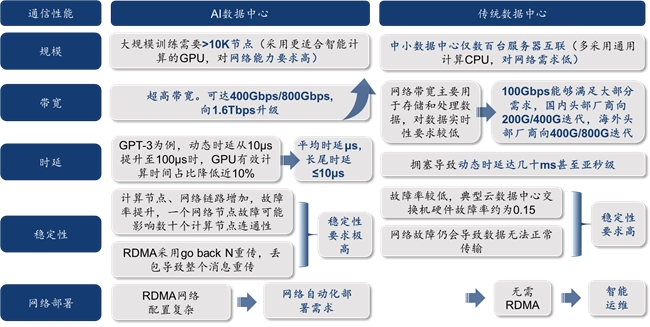
图9:AI数据中心相较传统数据中心,对通讯性能和后果条目大幅擢升

图10:左侧为传统数据中心汇聚三层树架构,右侧为AI数据中心三层脊叶架构
针对AI数据中心的低蔓延、大笼统、高并发等特色,传统的TCP/IP汇聚架构已无法得志应用的需求。因为传统的TCP/IP汇聚通讯使用内核来发送讯息,需要通过CPU来进行数据传输。这种通讯模式具有较高的数据出动和数据复制支拨,使得CPU需要阐发无数的公约支拨处理,从而导致更高的 CPU 负载和高流量,降速其他任务的速率。濒临这个问题,RDMA(Remote Direct Memory Access,良友径直内存造访)的横空出世,为从简数据传输设施,擢升通讯后果带来了本色意旨。与传统的IP通讯不同,RDMA绕过了通讯经由中的内核侵略,允许网卡绕开CPU,主机不错径直造访另一个主机的内存,大大减少了CPU支拨,将难得的CPU资源用于高价值的计较与逻辑限度上,从而擢升了合座汇聚笼统量和性能。
当今主流RDMA有缱绻包括三种,档次结构和汇聚硬件诱骗各不一样:
· IB(InfiniBand):是专为RDMA遐想的汇聚,最早由IBTA(InfiniBand Trade Association)在2000年控制推出。在遐想之初即保证可靠传输,在RDMA有缱绻中性能最优,硬件上需要使用InfiniBand专用的网卡和交换机。商场样式从开首的百花皆放,到现今英伟达/Mellanox的鹤立鸡群,生态较为闭塞。
· RoCE(RDMA over Converged Ethernet):RoCE通过以太网达成RDMA功能,不错绕过TCP/IP并使用硬件卸载,从而缩小CPU独揽率,擢升传输速率和功率,并缩小成本。2010年起,IBTA发布第一个能够交融于以太网运行的RDMA-RoCEv1,基于以太网链路层达成RDMA公约,但在汇聚层仍基于InfiniBand公约。2014年发布RoCEv2,将 RoCEv1的 InfiniBand汇聚层替换为UDP/IP公约 仅在传输层使用 InfiniBand传输层公约。RoCEv2使用撑合手RDMA流控技艺的以太网交换机和撑合手 RoCE的网卡。RoCE基于以太网,因此生态通达,“玩家”宽绰。
· iWARP(Internet Wide Area RDMA Protocol):基于TCP使用RDMA技艺,但比拟RoCE,大型组网时TCP连接仍会占用无数内存资源,数据传输后果仍较低,性能差于InfiniBand和RoCE。iWARP使用普通的以太网交换机,但需要撑合手iWARP的网卡。当今较少被使用。
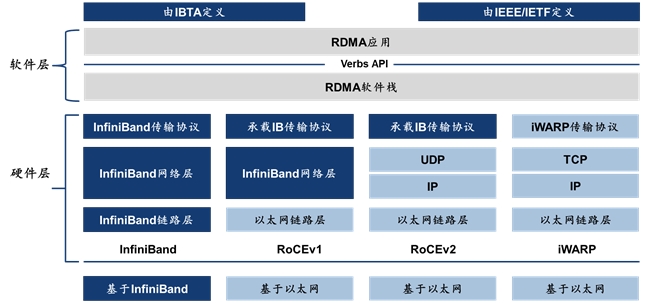
图11:IB、RoCEv1、RoCEv2、iWARP架构对比
(四) IB vs RoCE,汲取高速铁路如故高速公路?
从技艺和性能角度开拔,当今构建数据中心内这个数据“输送高速系统”的最主流的两正途线,就所以英伟达/Mellanox鹤立鸡群、别具肺肠的IB,以过火他厂商构成的“起义军”、基于传统以太网改良升级的RoCE。
更为平庸的阐述来看,要是把传统的通讯汇聚比作是国谈,那么IB就类似于一条另外新建的专有高速铁路,输送速率更快,后果更高,但只可跑基于轨谈的高铁;而RoCE就类似于基于现存的国谈升级改革成高速公路,匡助之前跑在国谈上的各样车型以更快的速率和后果通行。因此,IB等于一位“专精单项的高东谈主”,而RoCE则是一位“万能选手”。底下咱们就通过一张图表,来望望它们在性能、部署复杂性、生态、成本等方面的较量:


通过表格直不雅的对比,咱们不出丑出IB在传输性能、集群范围、运维等方面具备一定上风。因此,在短期里面分厂商受限于武备竞赛下的算力资源垂危,或是汲取借助IB的特色来快速搭建出集群用于模子检修,或是因本人组网才智不及径直汲取英伟达成套的有缱绻,IB在高性能计较领域暂时占据了更大的商场。但从中弥远来看,由于RoCEv2基于以太网这个愈加宽绰、通达的生态和更好的跨平台撑合手,且具有更低的硬件成本和更平素的供应商汲取,跟着其性能冉冉接近IB,将会凭借其更好的经济性和兼容性,取得愈加平素的商场。
天然,IB和RoCE都在连续演进以支吾明天的挑战,包括若何合手续提高可用性、若何撑合手更大范围的集群等。IB的明天版块将连续擢升带宽和缩小蔓延,以保合手其在高性能计较中的进形状位;而RoCE则可能通过改进流控机制和拥塞管理,提高其在大范围汇聚中的深入。此外,2023年7月硬件诱骗厂商博通、AMD、念念科、英特尔、Arista和云厂商 Meta、微软等共同创立了UEC(Ultra Ethernet Consortium,超以太网定约),极力于在物理层、链路层、传输层和软件方面开发新的通达式“Ultra Ethernet”治理有缱绻,旨在鼓吹高性能以太网的发展,以支吾增长的智能计较通讯需求。UEC定约当今已有约70家成员公司,国内的华为、新华三、星融元、阿里、腾讯、百度和字节等厂商亦是定约里的中枢成员。

图12:UEC定约成员示例
与此同期,咱们正惊喜地看到以太网追逐IB的脚步正在连续加速。从技艺阶梯来看,以太网依然紧追IB推出了800G的带宽居品,并有了1,600G的贪图,且在期间线上并不过期。从下旅客户来看,近期不管是Meta用于检修Llama的万卡集群,如故马斯克但愿打造的十万卡集群,都优先禁受了以太网的有缱绻。从竞争敌手来看,英伟达手脚IB的调换者,也同步推出了全新的Spectrum-X以太网汇聚治理有缱绻,并在近日加入了UEC定约,业界以为这是英伟达多年“孤立无援”后的第一次“趁势而为”。

图13:IB和以太网带宽阶梯图
(五) 在RoCE这条高速公路上,交换机、网卡和交换芯片是咱们以为国内产业发展的中枢基建
交换机、交换芯片和网卡是构建以太网基础设施最中枢的部件。其中,交换机是当代汇聚&数据中心基础设施的中枢组件,集成了各个中枢硬件和软件操作系统,阐发数据在汇聚中的传输和路由,全球主要供应商包括念念科、Arista、华为等。交换芯片手脚交换机里最中枢的部件,决定了交换机的端口速率和笼统量,技艺门槛高,全球中枢厂商包括英特尔、博通、Marvell等。网卡通过其物理接口与交换机相连,达成计较机与汇聚物理层的连接,决定了数据的传输和卸载速率,全球中枢供应商主要集会在Intel、英伟达和博通等。
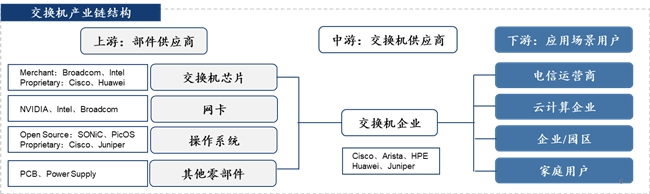
图14:交换机产业链
在交换机整机和操作系统层面,国内依然有一批具备全球竞争力的厂商,这其中既包括传统通讯大厂华为、新华三等,也包括走白盒阶梯的锐捷、星融元等,它们纷纷推出了当今业界最高带宽的、基于800G端口的51.2T自研交换机,在居品和治理有缱绻才智上并不过期于国外。但在中枢交换机芯片和网卡领域,国内尚有较大差距,国外厂商占据了绝大部分的商场份额。在交换芯片层面,国外大厂博通、Marvell等已启动批量出货51.2T的交换芯片,达成了老练的交易化,而国内的主流交换芯片还所以2.4T/3.2T为主,性能较弱无法得志大型互联网、数据中心的需求。在网卡层面,国外大厂供应给数据中心的网卡主流传输速率依然达到200G/400G bps的水平,并依然启动引入800G bps的网卡,但国内当今RDMA网卡的最高性能仍处于100G bps的水平。
合座来看,固然国内在交换芯片、网卡等层面尚有差距,但在基于以太网的集群集成、中枢交换机整机、光模块等领域均已有无数的冲破。咱们以为面前国内RoCE的产业阶段,粗略与当年的新动力汽车类似,最初在合座(整车/交换机整机)和某个中枢零部件(锂电板/光模块)启动冲破,再基于此带动系数产业链的全面冲破。
从行业发展来看,当今好多厂商仍旧坚合手着往日传统的闭塞软硬件系统和黑盒有缱绻,从硬件的芯片、网卡、交换机整机,到软件操作系长入起打包出售和请托。但咱们以为通达式的架构、开源的软硬件生态才是数据中心互联通讯明天的标的,举例白盒&软硬件解耦的交换机居品、基于开源比如SONiC(Software for Open Networking in the Cloud)的云原生&容器化的通用汇聚操作系统、基于RoCE的商用网卡和交换芯片等。咱们同样信服,只须坚合手通达、开源,打造泛在的生态定约,国内才有可能在这一领域达周至面的冲破。
(六) 赶走语
本期主要围绕数据中心内,极端是集群间Scale-out的互联通讯作念了粗浅的概述,咱们看好国内基于以太网的互联通讯生态的发展,该技艺阶梯亦然国内公司明天在濒临英伟达最有但愿达成追逐的标的之一。固然国内当今在交换芯片、网卡等硬件层面仍有差距,但依然有一批互联通讯领域的创业企业启动崭露头角,不错预料原土行业将会迎来一波新的发展机遇,尤其是基于通达、开源生态的商用居品和软硬件治理有缱绻厂商。
明天咱们会围绕互联通讯这一主题,在Die-to-Die互连、片间互联、板间互联等多个标的作念更多的共享和交流。CMC本钱将合手续聚焦数据中心领域的中枢技艺和产业发展趋势,依托基金团队丰富的产业布景和深刻瞻念察,并集会AI算法厂商、芯片遐想公司、晶圆厂、整机厂商等一线产业资源以及政府资源,在AI和算力基础设施领域进行全面布局,助力加速国产化的全面冲破。
参考贵寓:
中金公司连接部:“AI海浪之巅系列InfiniBand VS以太网,智算中心汇聚 需求迎升级”
中金公司连接部:“通讯技艺10年瞻望系列 224G PHY已登程,数据中心有线通讯迈向新征途”
|
