| 
转录组手脚扣问基因抒发的利器欧美av,照旧成为推行室的常用用具。那么拿到转录组的数据之后,动辄就有几十页的分析论述,几十项分析实质。每个图表的含义是什么,哪一些分析实质是需要要点关怀的呢?信得过不错用到著述里的分析实质又有哪些? 本次咱们对转录组结题论述里的参考基因组比对和数据库注视进行先容,以便捷诸位憨厚快速着手转录组结题论述。 真核转录组参考基因组比对和数据库注视是分析转录组数据的环节要津,不错匡助识别转录本、注视基因功能和相识生物学经过。底下是这两个要津的简要先容: 指挥学生频繁测序生成的reads要与参考基因组或参考转录组进行比对,是以最初需要获取参考基因组和参考转录组信息。 参考基因组比对 参考基因组是指该物种已有的全基因组序列信息以及注视文献,reads比对到参考基因组是数据分析的第一步,后头分析实质王人是基于reads比对适度分析的。 比对成果统计 比对成果指Mapped Reads占Clean Reads的百分比,是转录组数据期骗率的最径直体现。比对成果除了受数据测序质料影响外,还与指定的参考基因组拼装的优劣、参考基因组与测序样品的生物学分类干系遐迩(亚种)关联。通过比对成果,不错评估所选参考基因组拼装是否能知足信息分析的需求。 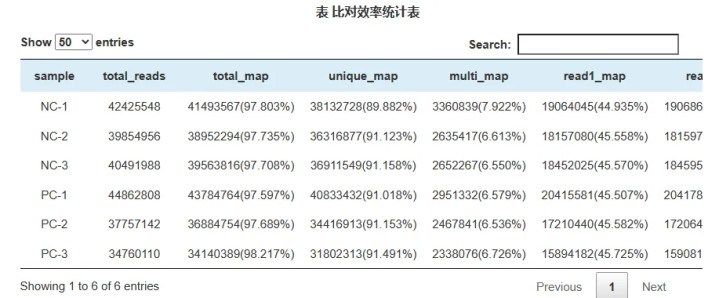
Mapped reads:比对到参考基因组(无参物种是unigenes)的reads,mapped reads并非严格条款100%比对,比对软件一般王人会有一定的容错率,一般reads与参考基因组允许最大错配为2个碱基。 Multiple mapped reads:比对到参考基因组多处位置的Reads数量。 Uniq Mapped reads:比对到参考基因组独一位置的reads。 mapping rate:比对到基因组的reads占clean reads的比值;比对率会跟着亲缘干系、基因组拼装质料、测序质料、有无沾污等有所波动,一般mapping rate大于60%,再低的话就要筹商进行无参拼装了。 基因组信息测完之后,接下来即是基因注视,识别这个基因是什么,算计这个基因编码什么卵白,有什么功能;当得到无参转录组之后需要重新拼接转录本,拼接的转录本功能也需要作念注视;当得到了互异抒发基因,念念作念下富集分析,就必须要了解每个基因对应哪个GO分类,亦然需要进行功能注视。 阔别出新基因(转录本)后,咱们会针对所有基因、已知基因、所有转录本和已知转录本四个角度区别进行6大数据库(NR、Swiss-Prot、Pfam、STRING、GO和KEGG)注视,全面得到基因和转录本的功能信息,并对各数据库注视情况进行统计。 一般是对已知基因和转录本的功能注视 关于转录本的基本功能注视频繁包括NR、GO、KEGG、COG/KOG、Swwiss-Port。 其中NR和Swiss-Port数据库是两个被无为使用的卵白数据库,其中Swiss-Prot是经过严格筛选去冗余的数据库。COG/KOG是基于基因居品的嫡派同源数据库,而GO和KEGG则是对基因功能和分子通路的数据库。 通过将转录本序列与上述数据库进行比对,就不错得到相对注成见功能注视信息,此后续扣问就不错通过注视信息进一步开展。 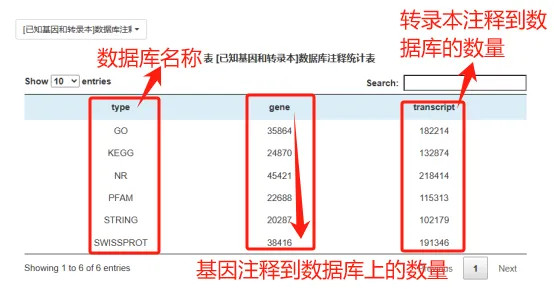 欧美av 欧美av
|
